
3 Tips You Need To Save Your Data Science Project Scope
As a data scientist, you expect to get a job that lets you do cool stuff - Big data, Big machine (or cloud, like the grown-ups), and Deep neural networks. Reality quickly creeps in as you realize the mismatch between your model, your project manager’s timeline, and your stakeholder’s expectation.
Your project is creeping further and further from the original scope, and you are miles away from completion. The demo is Tuesday, your eyes are watering and palms sweating.

Photo by Agê Barros on Unsplash. Quote added by the author via AdobeSpark.
“That’s not in the requirement!” - almost every developer
Previously, I wrote about the importance of defining data science scope with business stakeholders. It can save a lot of headaches by guiding the business from what they think they need to want they really want. Unfortunately, having a clear objective is not enough. Business requirements change all the time, what was important yesterday is not what is pressing today. And who knows about tomorrow? This post aims to discuss 3 tips (and a bonus one!) that you can use to manage your forever-changing data science project scope. To illustrate the points, let’s start with an all-too-familiar example.
. . .
Build a Churn Model, they said
As a running scenario, let’s pretend the retention rate is poor on your company’s new product. Your boss Bill tasked you to build a customer churn model to find out who is canceling their subscription. You spent a week gathering requirements, another two to clean the data, and you’re finally ready to get cracking.
Until.
Scope Creep: Let’s include some new data sources…
Bill the Boss decided that social media is essential in predicting the customer’s behavior. Which could be true, and it can be done, but your timeline didn’t change and you’re not getting paid more.

Scope creep example. Created by author.
Unfortunately for you, Bill said part of the budget for your project comes from the user engagement team. It’s a slap in the face if their data is not used. So now you gotta do it. Oh wait, did I mention that the data is so sparse it’s most likely going to get dropped anyway.
And then.
Scope Change: Let’s completely change our assumption…
Sometimes, when these “additional features” manifest themselves too far into the project, it becomes a scope change. As an example, a batched process that runs nightly has a fundamentally different architecture from a real-time prediction.
Scope change example. Created by author.
Let’s take a pause here and think back to when this happened to you. Take a look at the three options below related to scope creep or scope change. If you could go back in time and pick one, what would you do?

There are no right or wrong answers here (or ever), and these are all good approaches to take given the flexibility on the timeline and budget. Instead of trying to redefine or blindly completing the changes, what I would recommend is to ask more questions.
. . .
The scope change problem happened to the best of us. And although not all scope changes are bad (some are detrimental), they do put an unnecessary amount of stress onto us. Let’s dive into the tips that can hopefully save you some gray hair.
Tip 1: Know who your project stakeholders are
Once we get a defined project brief, it’s very natural for the problem-solvers amongst us to dive into development mode. These are the steps we typically take:
1⃣ Speak to the teams that have the data we need
2⃣ Train model
3⃣ Speak to the teams that will help us deploy the mode (such as data engineering and infrastructure teams, if you’re not lucky enough to be working with them already)
Cool, but what went wrong here?
Take a look at the complex organizational structure below. Most data science projects have multiple touchpoints within the organization. The disparate data sources that need to be curated, joint budget delivered by departments with differing needs, and supporting business functions that have the insights we need.
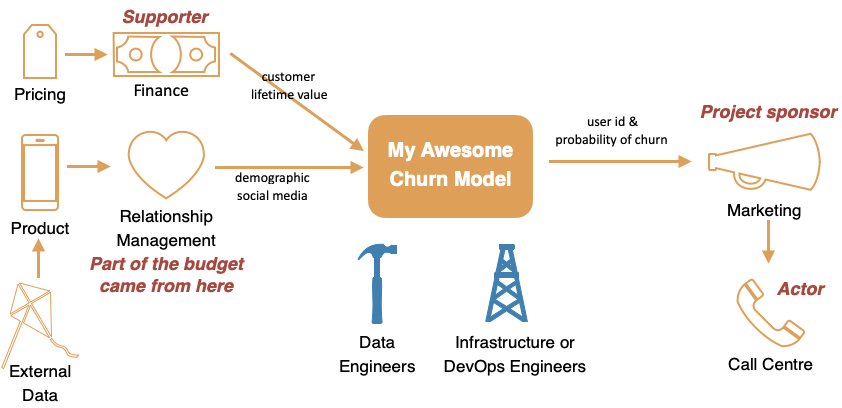
Complex organizational touchpoints for a simple machine learning model.
Created by author.
Without a firm grasp on the multitude of stakeholders, you realized…
❌ Your life-time-value calculation is incorrect because you did not know that the pricing team gave discounts to customers who signed up before the official launch.
❌ The product satisfaction index you created is a bad proxy to NPS because you did not know that the product team transformed it multiple times before passing it onto the relationship management team.
❌ Most importantly, you failed to understand who is the user of your model. The frontline call center employee needs to access prediction on short-notice. Perhaps, they also care less about precision and want to optimize recall.
Often, the change of scope results from not involving the right stakeholders at the beginning.
If we had known that the relationship management team funds the project, we would include metrics that they care about - be it NPS or the number of retweets. If we had known the call center employee is our user, we would include a robust model explainer - so they can optimize the first 3 seconds of a phone call before the customer puts their phone down with “No, I don’t need a new cellphone contract, for the third time this week”.
All of these stakeholders have needs that will creep into the project as time goes by. Mapping out the stakeholder matrix early on in the project is a great way to manage them throughout the project life-cycle.
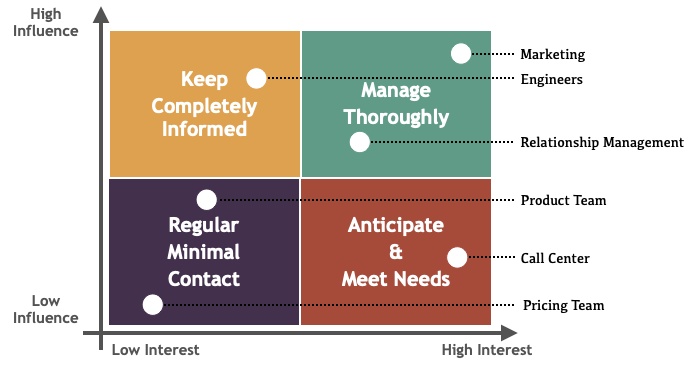
Example of the project stakeholder matrix (stakeholder placement will differ from a project-to-project basis). Created by Author.
There are a lot of good materials on stakeholder analysis out there, but the gist is this:
Don’t seek to satisfy everyone.
Classify the type of change requests by how important these stakeholders are to the success of your project.
Otherwise, you will be running out of time and budget.
Tip 2: Use a very-specific sentence to communicate the problem statement
A project often has multiple touchpoints and the feature requests may come flying in. You need to remember the objective of your project by creating one very specific sentence.
Use a very specific sentence to keep the objective in mind and the scope contained
Every time a request comes in, you can very quickly decide if it aligns with what you are trying to achieve.
For example, you can have a vague sentence that says:
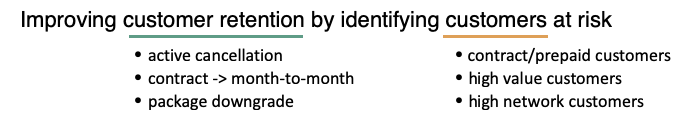
However, customer retention is a broad statement. Is active cancellation the only type of customer churn, or are package downgrade and lapsed subscription also included? Are we targeting just contract customers, or do we care more about high-value or high-reach customers?
The following three sentences are better examples of refined problem statements:
It helps to break the sentences down into four parts:
🔍 Identify/insights: is it a supervised or unsupervised problem? is it a classification or regression problem?
❓What is the metric we are trying to optimize: number of active cancellation, or conversion rate for outbound calls?
🙋♀ Who is it that we are targeting: all contract customers or just high-value customers who are eligible for an upgrade?
🕰 When should the prediction take place: does it need to have fast prediction time when the customers call in, or can it be a nightly batched process to create the outbound calls list for the next day?
If you cannot narrow down your sentence, then you most likely need to split your project into phases. For the churn model, you can start from identifying customer segments and use the results as an input feature to the active cancellation model.
Tip 3: Define non-ambiguous success metrics
During model training, a lot of ideas are thrown around and tested by multiple team members. The simpler the metric, the easier it is for us to quickly determine if our efforts are pushing towards the right direction. Instead of trying to balance both precision and recall, it is easier for our brain to comprehend just the F1 score. Instead of comparing the F1-score between Region A and Region B, it is easier to understand the weighted-F1-score between both regions.
A carefully chosen metric ensures that you are not fluffing around and tuning non-essential stuff
It’s fun to see that 0.1% of accuracy gains, but the investment is often not practical.
Sometimes, when you have multiple metrics (say n metrics) that cannot be combined, you should pick n-1 satisficing metric and just 1 optimizing metric:
👍 Satisficing metric: the good enough metric. Typically have a threshold, such as model size smaller than 5MB or runtime less than 1 second.
🚀 Optimizing metric: the metric to minimize or maximize. Typically have no bound, such as the highest accuracy I can get (theoretically it’s 100% but you get my point).
Having only one optimizing metric is the key to comparing multiple experiments. If we use the example from above:

👍 Satisficing metric: the speed of scoring to be below 2 seconds. This allows the call center agent to quickly decide if they want to offer this customer a better deal based on their probability of churn.
🚀 Optimizing metric: the F1-score of predicting cancellation. A balanced view is required, so we make sure we offer good deals to customers who are likely to churn but don’t give out too many good deals to those who might not.
Andrew Ng’s discussed the idea of choosing a single metric in his book - Machine Learning Yearning. I encourage everyone in the data profession to read this book. He also published a Structuring Machine Learning Projects course on Coursera on this topic (and more).
Bonus: Use a roadmap to track and show progress
Projects run over all the time, it’s not a big deal. What’s a big deal is when you tell your stakeholder you’re not done, on the day you’re supposed to be done. All that business wants is to know you have a plan - and that you are proactively tracking it.

Photo by Andy Beales on Unsplash.
“Unless commitment is made, there are only promises and hopes; but no plan.” ~ Peter F. Drucker
Data science projects have a host of challenges on top of traditional software projects: non-deterministic outcomes, accuracy or relevance uncertainty, opacity, fairness issues. These make AI a difficult sell to decision-makers and upper management.
It is understandable why we always shy away from giving a timeline for data science projects. But this creates two problems:
-
The lack of transparency makes it tremendously scary for business, so they keep micro-managing your every move.
-
It’s just too easy for you to get stuck in researching some tangentially-related cool new techniques than delivering business value.
Put together a roadmap to keep you, and everyone you depend on, accountable.

An example roadmap. Created by Author.
The roadmap needs to include at least the following 4 items:
1⃣ What you will do: the actual tasks that you will be doing, such as evaluate environment readiness, consolidating input data, or creating a baseline model. These should be in small sprints (say 2–6 weeks), so it’s easy to raise risks if it runs over.
2⃣ What they can get: not everything you do directly translate to an outcome that the business can use, but it’s important to try and fit your task to something they can consume. For example, after consolidating input data, it’s easy to put together a quick slide deck or dashboard to communicate your results. Businesses can play with the dashboard, interrogate the results, and perhaps even help you create a feature or two.
3⃣ When they can get it: give an estimated date on the completion of the task. Imagine you board a flight and the pilot tells you he’s not sure when you will get to your destination - variable wind speed and all. Commit to a date that you think is reasonable and raise concerns early to manage expectations.
4⃣ Protection against if things go wrong: in big projects, everyone has to work together and it is important to highlight that dependency to your stakeholders. Either they can help you chase after the team to give you the data you need, or they let you have another week finish.
Lastly…
Don’t be afraid to ask for help.
You never know what they’re going to say unless you ask. To my surprise, a former client decided to hire two additional resources when I explained to him that he can get the results he needs faster.
. . .
If you like this post, I have posted similar topics on this before:
. . .
Thanks for reading ⭐ Follow me on Medium, LinkedIn, or visit my Website. Also, if you want an evaluation of your machine learning deployment framework, email us at Melio Consulting.