
Launching Into Uncertainty - 6 Smart Steps to Future-Proof Your ML Models
There have been many articles focusing on how machine learning can and is helping during the pandemic. South Korean and Taiwanese governments successfully demonstrated how they used AI to slow the spread of COVID-19. French tech company identifying hot spots where masks are not being worn, advising where governments can focus on education. Data and medical professionals collaborating to index medical journal papers on COVID-19.

Photo by Anastasia Patrova from Unsplash.
Participation from the data science community is inspiring and the results are outstanding.
But this post is about the opposite. I am not here to tout the successes of machine learning. I am here to cast a little doubt on all its glory and wonders. I’m here to ask the question:
Are you watching your machine learning models during this uncertain time?
And why not?
Photo by Stephen Dawson from Unsplash.
Real-life data often diverges from training data. From the day you release the accurate, stable model into production, its performance has been degrading every day as your customers evolve. With COVID-19, it is as if the model is released from the safe, incubated Petri dish to the wild wild west.
With the policy changes, the interest rate drops, and the payment holidays, the sudden data shift can have a profound impact on your model. It’s okay to have a decrease in model accuracy, but it is not okay to be ignorant of the changes.
It’s okay to have a drop in model accuracy, but it is not okay to be ignorant of the changes
For the past couple of weeks, I have been involved in impact assessment for these machine learning models. It was overwhelming initially, so I gathered some practical steps in the hopes that other teams can approach the process with a bit more confidence and a bit less panic:
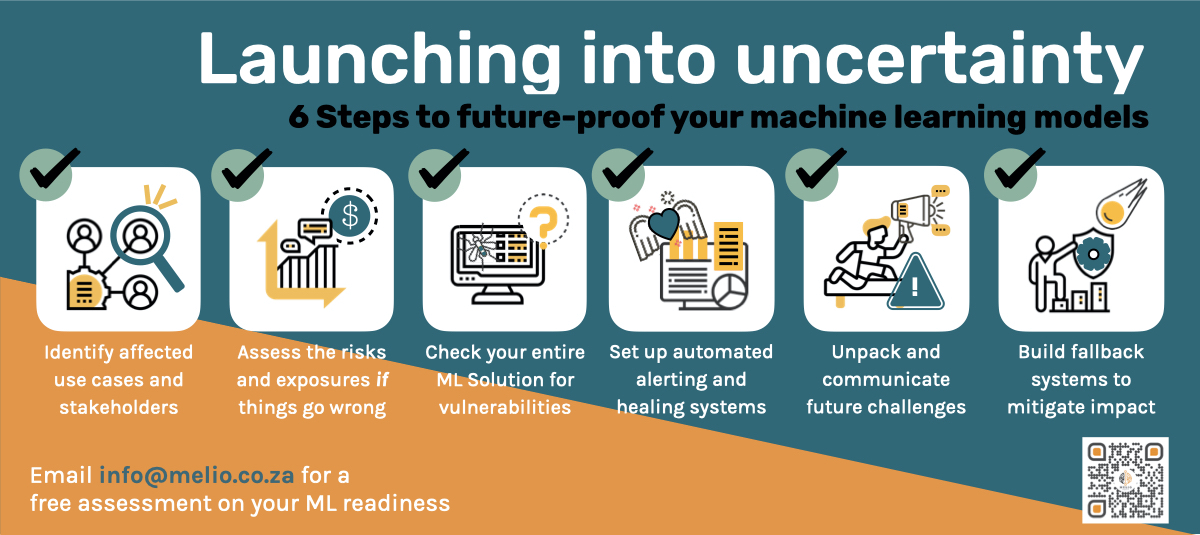
Photo by Stephen Dawson from Unsplash.
. . .
Step 1: Identify affected use cases and stakeholders
Icon from Eucalyp, adapted by Author.
Not all use cases will be affected by the pandemic, like not all models will suffer from data or concept drift.
The first step in any software assessment is the same as the first step in any software development: ask questions.
Ask a bunch of questions.
If you have many on-going use cases and not sure which to tackle first, begin by asking these:
❓ Am I modeling human behavior? (i.e. items purchased during Easter, home loans down payment)
❓Did I have any inherent assumptions about the government or corporation policies that have changed during the crisis (i.e. travel bans, payment holiday from the bank)
Once you have identified the use cases, then pinpoint the stakeholders affected by these use cases. The stakeholders are often subject matter experts in the domain, so they may be able to assist you in step 2 below.
Draw a decision tree for yourself.
If your system touched a human or a policy, carry on with Step 2.
Otherwise, move on.
Step 2: Assess the risks and exposures for when things go wrong
Icon from Eucalyp, adapted by Author.
This pandemic is a classic case of a black swan event. It’s a rare and unexpected virus outbreak with severe consequences.
So the chances are, things are going to go wrong, but how wrong?
Things are going to go wrong, but just how wrong?
Scenario analysis can help us navigate these extreme conditions.
Speaking to the SME (subject matter experts) from the business is incredibly valuable in this step. They often have many questions they want answers to, and data scientists would analyze the data to generate insight packs to these questions. This is the time when these questions can help you interrogate your models.
As an example,
“What happens to our bottom line if real estate sales are decimated?”
Well, this is the time to test it out. If you are modeling the revenue generated from home loans, then examine the data when home loan sales are low (winter months in a summer vacation town). From there, tweak it with the suggestions from the SME and generate a fake input dataset and run it through your model. This can help you assess the areas when the model is at risk.
Giving a quantitative number can help businesses make tough decisions. Even though we feel like we don’t have enough information to provide a prediction, decisions still have to be made. Loans still need to be granted and toilet papers still need to be shipped. Instead of pushing the responsibilities further along the chain, we should focus on doing the best we can.
Give a prediction with all the asterisks attached to it.
If the impact is large, proceed to step 3 for a thorough examination.
Otherwise, move on.
Step 3: Check your entire solution for vulnerabilities
Icon from Eucalyp, adapted by Author.
Machine learning solutions are more than the model itself. There is the data engineering pipeline, inference, and model retraining. It is important to scan the entire solution end-to-end to find vulnerabilities.
Machine learning solution is more than just the model
Here are some areas you can look at:
⏩ Will a bulk quantity break your pipeline? Some supplier’s predictive algorithms were broken by a sudden change in order quantity. On the other hand, some fraud detection systems were overwhelmed by false positives.
⏩ Has the baseload on your infrastructure changed? Some models are less relevant and some are even more important, shifting your computing resources can even out the cost.
⏩ Investigate the global and local feature-importance of your model. Are your top features sensitive to the pandemic? Should they be? There are many articles about explainable AI, and in the time of the unknown, inference explainability could give the transparency people need.
Define checks throughout your entire pipeline.
By the time you reached Step 3, you already determined that your solution is affected by the crisis. So carry on to Step 4.
There is will be no moving on from this point on, only moving forward.
Step 4: Set up automated alerting and healing
Icon from Eucalyp, adapted by Author.
If you are reading this article, you probably don’t have monitoring systems in place. Otherwise, you would be setting up 500 Jira tickets and be on top of your next steps.
Deploying a machine learning model is like flying an airplane
☑️ : Having no logging is like flying without a Blackbox. Any terrorist can hijack the plane without any consequences.
🖥️ : Having no monitoring is like flying blind in new airspace. The pilot has no idea where he’s going, and neither do you.
🌪️️: Having no resilient infrastructure is like flying with an unmaintained engine. The ticket is cheap but the plane could go down at any time.

Photo by Kaotaru from Unsplash, edited by melio.ai
You won’t board a plane with a blind pilot and a broken engine, why would you deploy a model without logging, monitoring, and resilient infrastructure?
Let’s set aside monitoring, what about healing?
. . .
Many matured machine learning solutions have automated retraining built into the system. But in these extreme events, it may be worth taking a look at the refreshed models. Are they using the latest data for the prediction? Should they be?
Automatically redeploying the refreshed models could be risky when facing the unknown. A human-in-the-loop approach could be both an interim and a strategic solution.
1️⃣ Setup automated retraining and reporting (with business KPI as well as the spot checks defined in Step 3).
2️⃣ Alert a human for approval, with more stringent alerting criteria during the pandemic period.
3️⃣ If Steps 1–3 were conducted rigorously, and the risks and exposures acknowledged, then we may be ready to redeploy the models.
Monitor data and model drift and redeploy if necessary.
If you are still not sure, set-up canary deployment and redirect a small portion of your traffic to the new model. Then slowly phase out the old one when the new model is stable.
Step 5: Unpack and communicate future challenges
Icon from Eucalyp, adapted by Author.
The COVID-19 impact ranges from short-supply of toilet paper to a meltdown of the global economy. Most if not all industries are affected, either positively or negatively.
The abnormality may become the new norm
Long term effects such as remote working, a surge in bankruptcy, structural unemployment as well as travel restrictions are unclear. When the historical data is not applicable in this unprecedented situation, the “abnormality” may become the new norm. This forces us to go back and unpack the fundamental business question and rethink many assumptions.
⏩ Do we include the pandemic data into future model training?
⏩ Do we include new features that better reflects the current reality?
⏩ Should we tune the model sensitivity when major disruptions occur?
⏩ Do we need to re-evaluate the model metrics chosen before the pandemic?
⏩ Do we revert all the above when things “return to normal”?
There are more questions than answers at this stage. It would be premature to blindly recommend “best practices”.
The only way is to stay curious, keep communications open, acknowledge risks, and take it one step at a time.
Step 6: Build fallback systems to mitigate the impact
Icon from Eucalyp, adapted by Author.
Have you wondered why dung beetles don’t get lost?
These tiny insects use a combination of guiding systems to help them achieve the highest precision possible. When one system is not reliable, they switch to use another.
When you don’t have any data, you have to use reason ~Richard Feynman
The famous physicist and Nobel Laurette Richard Feynman, on investigating the NASA Challenger program disaster said: “When you don’t have any data, you have to use reason.” (extracted from Range by David Epstein, Chapter 9).
This particularly rings true when machine learning depends on historical patterns. When historical patterns are not reliable, alternative strategies need to be called upon:
⏩ Unsupervised or semi-supervised approaches can help redefine the problem space. Create new segmentations for existing users based on their new behaviors. A past outdoor junkie could be the now mindful yogi.
⏩ Stress-testing: the scenario analysis framework set up in Step 2 can be used to load various extremes of input data.
⏩ Ensemble or Choose: Ensembling is popular owing to its ability to create a strong learner by combining multiple weak learners. Sometimes, that may not be necessary. It is possible to have multiple models for one use case. The engineering pipeline can detect changes or attributes, and use the most appropriate model for inference.
Or all the above, with the human-in-the-loop.
And that is why ladies and gentlemen - AutoML is not going to replace data scientists. Be the voice of reason. Chat to the SMEs. Keep calm and carry on.
. . .
Navigating changes in this uncertain time is challenging. Nobody is certain of anything, and it can be daunting to make a prediction. Following these steps can guide you through unforeseen problems:
1️⃣ Go back to fundamentals, what is this use case about?
2️⃣ Question & explain your model
3️⃣ Spot check your entire solution
4️⃣ Set up logging & monitoring framework
5️⃣ Retrain and redeploy
6️⃣ Future-proof yourself by staying curious
7️⃣ Be the voice of reason, keep calm and carry on
. . .