
What the Ops are you talking about?
The software industry has been obsessed with the various ops-terms since the popularisation of DevOps in the late 2000s. Ten years ago, software development to deployment has a throw-over-the-world approach. A software engineer develops the app, then throw it over to the operational engineers. The app breaks often during deployment and creates significant friction between the teams.

Photo by Kelly Sikkema from Unsplash, edited by Author.
The DevOps practice came about to smooth out the deployment process. The idea is to treat automation as a first-class citizen to build & deploy software applications.
This approach revolutionised the industry. Many organisations started building a cross-functional team to look after the entire SDLC. The team would set up the infrastructure (infra engineer), develop the app (software engineer), build the CI/CD pipeline (DevOps engineer), deploy the app (every engineer), then monitor and observe the app continuously (site-reliability engineer).
In a big team, different engineers have one primary function. But in smaller teams, one engineer often fills many roles. The ideal is to have many team members able to fill multiple functions so the bottlenecks and key-man dependencies are removed. So in reality…
DevOps, instead of it being a job function, is more practice or culture. It should be adopted at the beginning of building any software
Together with the rise of DevOps, a variety of ops are born.
The various Ops that exist in the software development world. Generated by Autor.
SecOps has security at the core, GitOps strive for continuous delivery, NetOps ensures the network can support the flow of data and ITOps focuses on the operational tasks outside of software delivery. But together, the cornerstone of these ops is derived from the vision that DevOps promises:
To get software out there as fast as possible, with minimal errors.
. . .
Five years ago, the phrase Data is the new Oil became all the hype. Leaders around the world started pouring resources into building Big Data teams to mine these valuable assets. The pressure for these teams to deliver was immense — after all, how can we fail with the promise of the new oil? With the rapid expansion, the analytics teams had also experienced their fair share of grief.
Then we made it all happen.
Data scientists became the sexiest career in the 21st century. We build ourselves up and are sitting in the golden age of data and analytics. Every exec has a dashboard. A dashboard with data from across the organisation and the predictive model embedded. Every customer has a personalised recommendation based on their behaviours.
But now adding a new feature takes weeks if not months. The data schema is a mess and nobody knows if we are using the definition of an active customer from credit team or marketing team. We became wary of rolling models out into production because we’re not sure what it will break.
So the data-centred communities stood together to pledge against inefficiencies seeded from badly managed data processes. Since then, a variety of data-centred ops are also born…

The various Ops that are born in the data-centred teams: DataOps vs. MLOps vs. AIOps. Generated by Autor.
. . .
DataOps 🆚 MLOps 🆚 DevOps (and AIOps?)
*Note: In this article, analytics teams refer to traditional BI teams using SQL/PowerBI to generate insights for business. AI teams refer to teams using Big Data technology to build advanced analytics and machine learning models. Sometimes they’re the same team, but we’re going to keep them separate so it’s easier to explain the concepts.
To understand all these different ops, let’s set the scene on how the data flows through the organisation:
- Data is generated by customers interacting with software applications.
- The software stores the data in its application database.
- The analytics team builds ETLs off these application databases from teams across the organisations.
- Analytics teams build reports and dashboards for business users to make data-driven decisions.
- The data engineers then ingest the raw data, consolidated datasets (from analytics teams) and other unstructured datasets into some form of a data lake.
- The data scientists then build models from these massive datasets.
- These models then take new data generated by the users to make predictions.
- The software engineers then surface the predictions to the users, and the cycle continues…
We know that DevOps is born because of the friction created between the development and operations team. So, imagine the headache that ensued from a 4-way interface, between the ops, software, analytics, and AI teams.
To explain how the different ops come in solving the processes above, here’s a graph plotting some of the the tasks that each job function performs across the timeline.
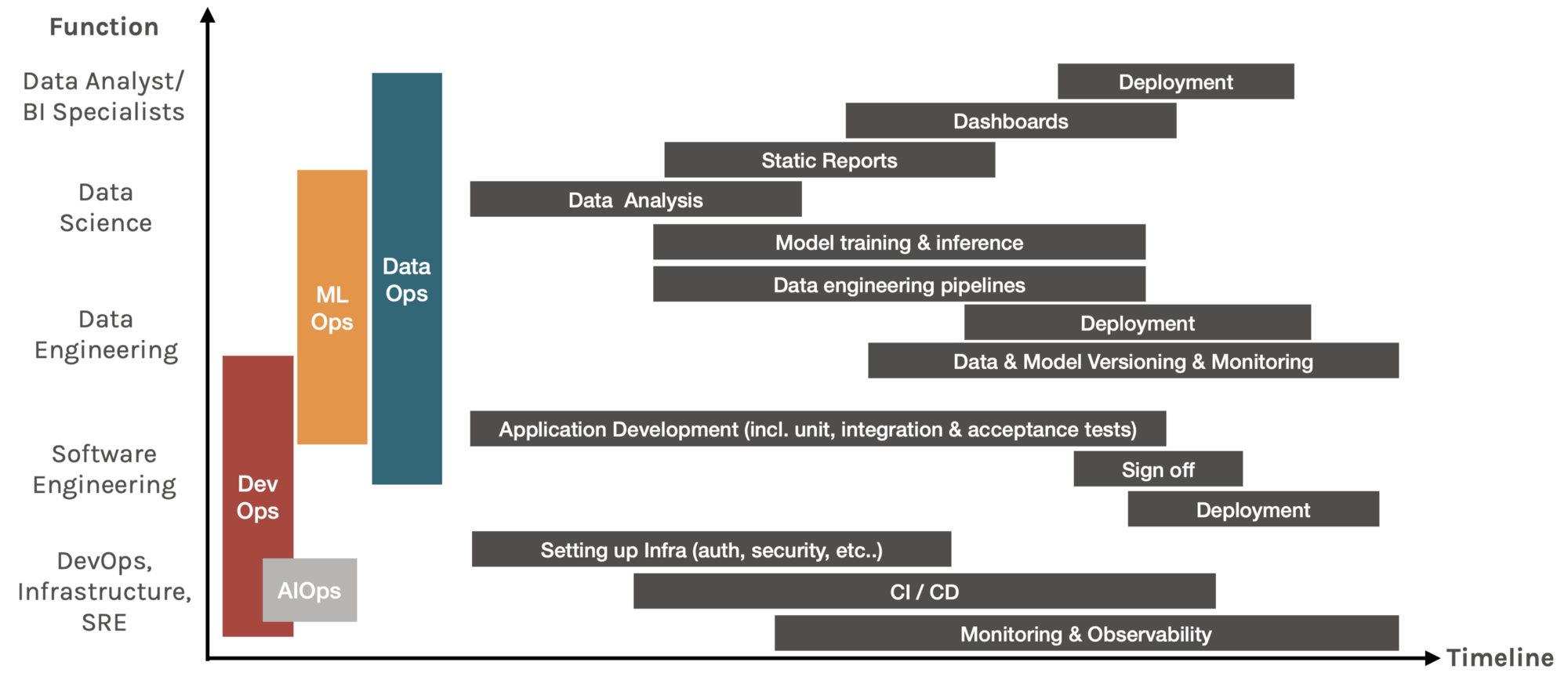
A graph of the tasks that each job function performs across the timeline. Generated by Author.
Ideally, the X-Ops culture should be adopted at the inception of the project and the practices implemented throughout. To summarise, this is what each Ops means:
DevOps delivers software faster
A set of practices aims to remove the barriers between the development and operations team to build & deploy software faster. It is usually adopted by the engineering teams, including DevOps engineers, infrastructure engineers, software engineers, site reliability engineers and data engineers.
DataOps delivers data faster
A set of practices to improve the quality and reduce the cycle time of data analytics. The main tasks in DataOps include data tagging, data testing, data pipeline orchestration, data versioning and data monitoring. Analytics and Big Data teams are the main operators of DataOps, but anyone who generates and consumes data should adopt good DataOps practices. This includes data analysts, BI analysts, data scientists, data engineers, and sometimes software engineers.
MLOps delivers machine learning models faster
A set of practices to design, build and manage reproducible, testable and sustainable ML-powered software. For Big Data/Machine Learning teams, MLOps incorporate most DataOps tasks and additional ML-specific tasks, such as model versioning, testing, validation and monitoring.
Bonus: AIOps enhances DevOps tools using the power of AI
Sometimes people incorrectly refer to MLOps as AIOps, but they’re quite different. From Gartner:
AIOps platforms utilize big data, modern machine learning and other advanced analytics technologies to directly and indirectly enhance IT operations (monitoring, automation and service desk) functions with proactive, personal and dynamic insight.
So AIOps typically are DevOps tools that uses AI-powered technology to enhance the service offerings. Alerting & anomaly detection offered by AWS CloudWatch is a good example of AIOps.
💎 Principals not Job Roles
It is a misconception that in order to achieve the efficiency that these ops promise, they need to start with choosing the right technology. In fact, technology is not the most important thing.
“DataOps, MLOps and DevOps practice must be language-, framework, platform and infrastructure agnostic.”
Everyone has a different workflow, and that workflow should be informed by the principals — not the technology you want to try, or the technology that is the most popular. The trap of going technology first will be if you want to use a hammer, everything looks like a nail to you.
All the ops have the same 7 overarching principals, but each with its own slight nuances:
1. Compliance
DevOps typically worries about network & application security. In the MLOps realm, industries such as finance and healthcare often require model explainability. DataOps need to ensure the data product is compliant with the laws such as GDPR/HIPPA.
🔧 Tools: PySyft decouples private data for model training, AirCloak for data anonymisation. Awesome AI Guidelines for a curation of principals, standards and regulations around AI.
2. Iterative Development
This principal stems from the agile methodology, which focuses on continuously generating business value in a sustainable way. The product is designed, built, tested and deployed iteratively to maximise the fail fast and learn principal.
3. Reproducibility
Software systems are typically deterministic: the code should run exactly the same way every time. So to ensure reproducibility DevOps only needs to keep track of the code.
However, machine learning models are often retrained because of either data drift. In order to reproduce the results, MLOps need to version the model and DataOps need to version the data. When being asked by an auditor which data was used to train which model to produce this specific result, the data scientist needs to be able to answer that.
🔧 Tools: experiment tracking tools, such as KubeFlow, MLFlow or SageMaker all have functionalities that link metadata to the experiment run. Pachyderm and DVC for data versioning.
4. Testing
Testing for software lies in unit, integration, and regression testing. DataOps require rigorous data testing, which can include schema changes, data drifts, data validation after feature engineering, etc. From ML perspective, model accuracy, security, bias/fairness, interpretability all need to be tested.
🔧 Tools: libraries such as Shap & Lime for interpretability, fiddler for explainability monitoring, great expectation for data testing.
5. Continuous Deployment
There are three components to the continuous deployment of machine learning models.
- The first component is the triggering event, i.e. is the trigger a manual trigger by a data scientist, a calendar schedule event and a threshold trigger?
- The second component is the actual retraining of the new model. What are the scripts, data and hyperparameters that resulted in the model? Their versions and how they are linked to one another.
- The last component is the actual deployment of the model, which must be orchestrated by the deployment pipeline with alerting in place.
🔧 Tools: most workflow management tools have this, such as AWS SageMaker, AzureML, DataRobot, etc. Open-source tools such as Seldon, Kubeflow KFServing.
6. Automation
Automation is the core-value of DevOps, and really there are a bunch of tools specialised in different aspects of automation. Here are some resources for machine learning projects:
7. Monitoring
Software applications need to be monitored, so does machine learning model and the data pipeline. For DataOps, it’s important to monitor the new data’s distribution for any data and/or concept drift. On the MLOps side, in addition to model degradation, it is also paramount to monitor adversarial attacks if your model has a public API.
🔧 Tools: Most workflow management framework has some form of monitoring. Other popular tools include Prometheus for monitoring metrics, Orbit by Dessa for data & model monitoring.
. . .
Conclusion
Adopt the correct X-Ops culture to speed up the delivery of your data-, and machine learning-powered software product. Remember, principals over technology:
1️⃣ Build cross-disciplinary skills: Nurture T-shaped individuals and teams to bridge the gap and align accountability
2️⃣ Automate early (enough): Converge on a technology stack and automate processes to alleviate engineering overhead
3️⃣ Develop with the end in mind: Invest in solution design upfront to reduce friction from PoC to production
. . .
Thanks for reading. If you want to know more about cloud-native tech and machine learning deployment, email us at melio.ai.